One of the defects of CUTE is that it was not designed to simultaneously support a multi-platform environment, that is instances of the environment that could be used simultaneously from a central server on several (possibly different) machines at the same time. Moreover, using CUTE on a single machine in conjunction with several different compilers (a case that frequently occurs when testing new software) is impossible. Furthermore, handling different instances of the environment corresponding to different sizes of the tools (that is the size of the test problems that they can handle) is also impossible. The reason for these difficulties is that the structure of the CUTE files, as described in [1], does not lend itself to such use, since it only contains a single subtree of objects files. If we call the combination of a machine, operating system, compiler and size of the tools an architecture, the obvious solution is then to allow several such subtrees in the installation, one for each architecture used.
However, as soon as the possibility of using architecture dependent subtrees is raised, the proper identification of the parts (scripts, programs) of the environment that are independent of the architecture also become an issue. Since it would be inefficient to store copies of these independent scripts and programs in each subtree, it is natural to store them in a data structure which is itself disjoint from the dependent subtrees. Finally, the multiplication of subtrees containing sometimes very similar but yet vitally different data makes the maintenance of the environment substantially more complicated, and therefore requires enhanced tools and a clear distinction between the parts of the environment that are related to testing optimization software and those related to its own maintenance.
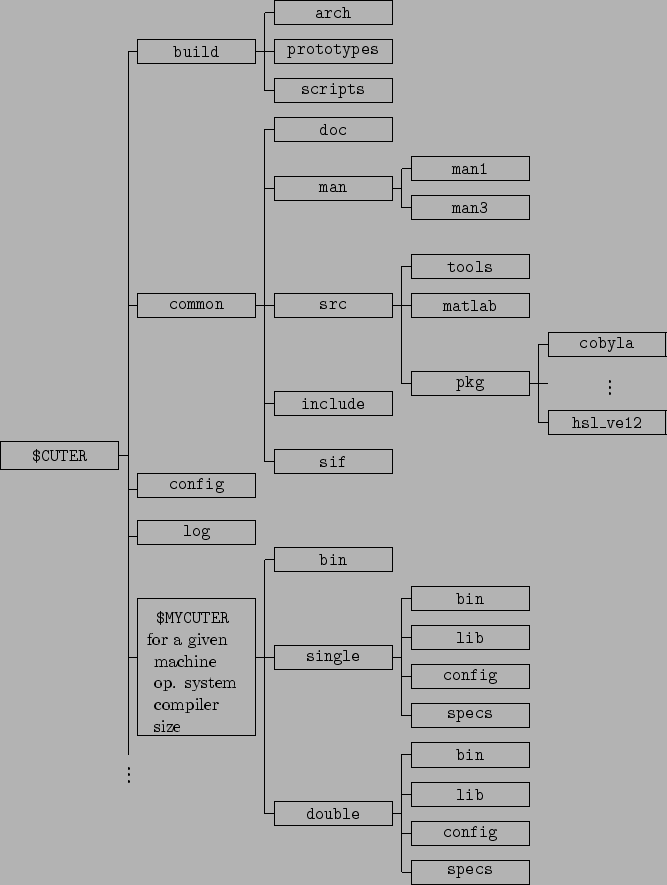
The directory organization chosen for CUTEr, shown in Figure 1.1, reflects these preoccupations. We now briefly described its components.
Starting from the top of the figure, the first subtree under the main $CUTER directory (the main root of the CUTEr environment) is build, which essentially contains all the files necessary for installation and maintenance. Its arch subdirectory contains the files defining all possible architectures that are supported by CUTEr, allowing the user to install new architecture dependent subtrees in an evolving manner, depending on the testing needs, the evolution of the platforms, systems and compilers. The prototypes subdirectory contains the parts of the environment which have to be specialized to one architecture before it can be used. We call such files prototypes and the process of specializing them to a specific architecture casting. The prototype files include a number of tools and scripts whose final form typically depends on compiler options and the chosen size of the tools. Finally, the last subdirectory of build, named scripts, contains the environment maintenance tools and various documentation files.
The second subtree under $CUTER is called common and contains the environment data files that are relevant for its purpose, the testing of optimization packages, but that are independent of the architecture. Its first subdirectory, doc, contains a number of documentation files concerning the environment (such as a description of its structure, the description of procedure to follow for interfacing the supported optimization packages, the complete SIF reference document, ...), but not a description of the CUTEr tools and scripts themselves. These are documented in the man subdirectory (and, as is common on Unix systems, its man1 and man3 subdirectories). The src subdirectory contains a number of subdirectories that contain the source files for many of the environment utilities: tools contains the sources of the Fortran tools used in user's programs, while matlab contains all the ``m-files'' that provide a MATLAB interface to the environment. The pkg subdirectory of src is used to stored the information related to the various optimization packages for which CUTEr provides an interface. There is one subdirectory for each such package (we have represented that for the COBYLA and VE12 packages), typically including an algorithmic specification file or the source code of the package if available. The subdirectory include of common contains the necessary header files for the interfaces between CUTEr and C codes. The last subdirectory of common, sif, contains a few test problems in SIF format.
The next subdirectory under $CUTER is called config and contains all the configuration and rules files which are relevant to umake when the latter is used to bootstrap the various Imakfiles in order to create the necessary Makefiles.
The log subdirectory of $CUTER contains a log of the various installations (and, possibly, subsequent un-installations) of the environment for the various architectures.
The remaining subdirectories of $CUTER are all architecture dependent: each of them corresponds to the installation of CUTEr on a specific machine, for a given operating system and compiler and for a given tool size. The figure only represents one, but the continuation dots at the bottom of the leftmost vertical line indicate that there might be more than one. The name of these directories are (by default) automatically chosen at installation, but a user of one of these subtrees would typically give it a symbolic name, like $MYCUTER, to refer to the instance of CUTEr currently in use. Each architecture-dependent subtree is divided into its single and double precision instances (single and double, respectively), each of these containing in turn four subdirectories. The first, bin, contains the object files corresponding to the optimization packages driving programs and, if relevant, of the package codes. The second, lib, contains library of cute tools and, if relevant, libraries associated with the interfaced optimization packages. The config subdirectory contains the architecture dependent files that were used to build the current $MYCUTER subtree (they are reused when a tool or optimization package is added or updated), while specs contains the algorithmic specification files for the optimization packages that are architecture dependent, if any. Finally, $MYCUTER/bin contains those scripts which are architecture-dependent, but not precision-dependent.
The fact that the CUTEr tools are now stored in the form of libraries (while they were stored as a collection of individual object files in CUTE), is another novel feature. This allows a much simpler design of new optimization package interfaces, since the interface no longer need to specify the exact list of tools which have to be loaded together with the package.
A final new feature of the environment organization is that the documentation is available via the usual man command for the scripts and tools, and both in acsii and pdf formats for the rest. It is hoped that this will make access to the relevant information more convenient for users.